A naive implementation of a queue on a relational database runs into two practical problems at scale:
- Claim contention. Many consumers repeatedly
SELECTthe same head-of-queue rows, then compete to lock or update them. Most consumers lose the race, retry, and waste CPU and I/O. - WAL and I/O costs. Common queue patterns that delete or rewrite rows generate a lot of WAL and index churn. That increases disk I/O, checkpoint pressure, and replication bandwidth.
PostgreSQL provides two features that directly address these problems:
FOR UPDATE SKIP LOCKED— lets a consumer atomically read and lock the next available items. This reduces contention and raises throughput. so competing consumers immediately skip locked rows. A benchmark measured improved end-to-end message throughput by about 28%.UNLOGGEDtables — skip WAL for table data, reducing WAL volume and WAL-driven I/O for workloads. A benchmark measured that the logged table produced roughly 30× more WAL than the unlogged table.
Benchmark details and scripts are in pgqrs git repo.
Why PostgreSQL as a queue ? Link to heading
PostgreSQL as a queue is a right choice when:
- Less Operational Complexity: The database can be used for both application data and queues at low or medium scale.
- Atomicity: If application data is in the same database, both the application state and associated queue item state can be updated in the same transaction.
However, there are limits (scale, reliability and business logic) beyond which a dedicated and decoupled queuing system is the better choice.
FOR UPDATE SKIP LOCKED Link to heading
The most common pattern to fetch messages from a queue table is to select and delete rows in a transaction. An example python code is:
def claim_then_delete(conn, batch_size):
try:
with conn.cursor() as cur:
cur.execute("""
SELECT msg_id
FROM my_queue
WHERE status = 'PENDING'
ORDER BY msg_id ASC
LIMIT %s
""", (batch_size,))
rows = cur.fetchall()
msg_ids = [r[0] for r in rows]
if not msg_ids:
conn.commit() # nothing to do
return 0, []
# Use parameterized query; pass a tuple for ANY(%s)
cur.execute("DELETE FROM my_queue WHERE msg_id = ANY(%s)", (tuple(msg_ids),))
# cur.rowcount gives number of deleted rows
deleted_count = cur.rowcount
conn.commit()
return deleted_count, msg_ids
except Exception:
try:
conn.rollback()
except Exception:
pass
raise
At scale this breaks down. Every consumer sees the same top rows, all attempt to lock them, and only one succeeds. The rest retry the same query, moving in lock-step and creating unnecessary contention.
Postgres provides FOR UPDATE SKIP LOCKED. With this clause, rows that are already locked by
another transaction are skipped, so each consumer can claim a different set without colliding.
A typical implementation looks like this:
def claim_and_delete(conn, batch_size):
try:
with conn.cursor() as cur:
cur.execute("""
WITH cte AS (
SELECT msg_id
FROM my_queue
WHERE status = 'PENDING'
ORDER BY msg_id ASC
LIMIT %s
FOR UPDATE SKIP LOCKED
)
DELETE FROM my_queue t
USING cte
WHERE t.msg_id = cte.msg_id
RETURNING t.msg_id;
""", (batch_size,))
deleted = [row[0] for row in cur.fetchall()]
conn.commit()
return len(deleted), deleted
except Exception:
try:
conn.rollback()
except Exception:
pass
raise
Selection and locking happen in one step. Consumers don’t fight over the same rows. The locked rows are deleted in the same transaction and returned to the application.
The graph shows that the throughput using FOR UPDATE SKIP LOCKED is much higher than for the naive
approach.
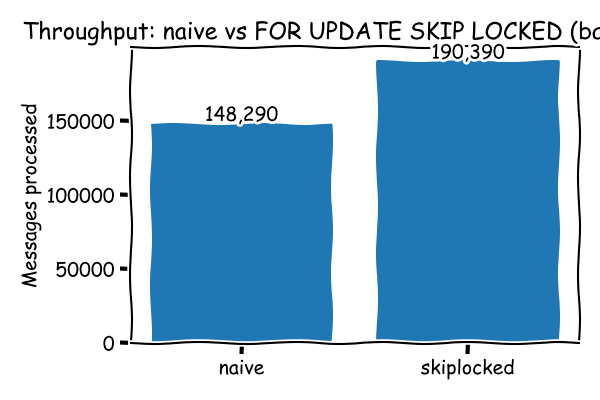
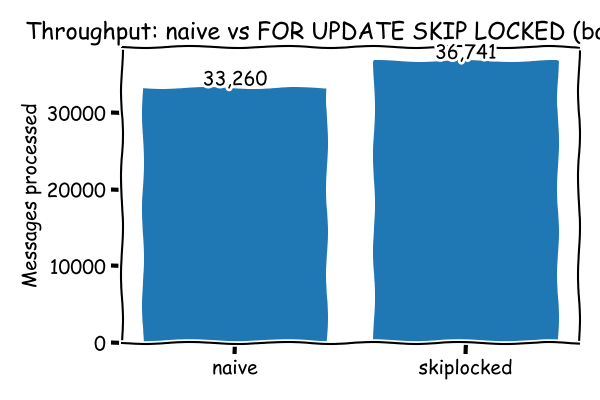
Batch size makes a difference. The above graph is for batch size=10 i.e. a consumer consumes
up to 10 messages if available.
With batch size=1, the throughput improvement is lower because there are more operations to
consume the same number of messages.
UNLOGGED Tables Link to heading
Postgres writes every change to the WAL so that data can survive crashes and be replicated to standbys. For a queue this can be wasted work. File I/O required to maintain a WAL may hinder high-throughput use cases.
UNLOGGED tables skip WAL writes:
CREATE UNLOGGED TABLE queue_foo (
msg_id bigserial primary key,
payload jsonb not null,
vt timestamptz not null,
read_ct int not null default 0
);
The trade-offs are:
- Faster writes: no WAL traffic means less disk I/O and higher throughput.
- No durability on crash: if Postgres restarts after a crash, the table is truncated.
- No replication: unlogged data does not stream to replicas.
For workloads where the queue is ephemeral, where upstream can replay, or where strict durability
is not required, UNLOGGED tables are an easy way to reduce overhead.

Conclusion Link to heading
FOR UPDATE SKIP LOCKED is an essential feature for implementing scalable queues in PostgreSQL.
Use UNLOGGED only if you can accept the loss trade-off.
Typical acceptable cases:
- Messages are replayable by producers or by a separate durable store.
- The queue is a local performance optimization and losing recent messages after a crash is tolerable.
- You need to reduce WAL bandwidth to save disk I/O, WAL archive space, or replication traffic.
Do not use UNLOGGED if:
- Durability is required.
UNLOGGEDtables are truncated on crash. - You rely on streaming replication to copy the queue to standbys.
UNLOGGEDtables do not replicate.
pgqrs implements these features in a Rust queue library built on PostgreSQL.